tags:
- ArchNUMA Systems
Explore for more:
From UMA to NUMA
在过去,所有的处理器都通过统一的总线去访问统一共享的内存和 I/O 资源,这种系统架构被称为基于总线的系统。在这个时期的主板上,除了 CPU 之外,还有南桥芯片和北桥芯片,其中北桥芯片负责内存控制、南桥芯片负责 I/O 控制。处理器会通过前端总线于北桥通信,从而访问内存。
在这种架构下,所有处理器核心访问内存的路径和速度是完全一致的,因此被称为统一内存架构(Uniform Memory Architecture, UMA)。采用 UMA 架构的处理器系统也被称为对称多处理器(Symmetric Multi-Processor, SMP)系统。
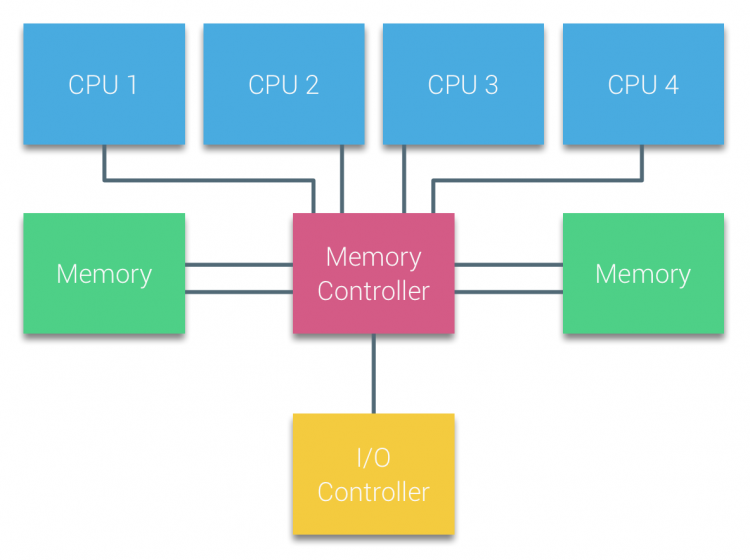
随着系统性能的提升和核心数量的增加,采用 UMA 架构可能会带来一些问题:
- 当 CPU 数量增加时,所有处理器共享同一内存总线,平均下来每个 CPU 能获得的可用带宽会下降。
- CPU 增多意味着总线长度和负载增加,在技术不变的情况下,这会导致总线延迟上升,影响整体性能。
本来 CPU 和内存的速度差距就在不断拉大,总线延迟的增加只会让这一情况变得更糟,所以长期来看,UMA 肯定不可取。而且随着技术进一步发展,传统的南桥和北桥芯片的功能逐步被集成在一颗处理器芯片中,形成片上系统,即 SoC (System on Chip)。片上系统的一颗处理器可能有许多核心节点。而这些节点在 die 上的分布可能并不均匀。如果想要设计高速的 symmetric interconnected system 会很复杂,所有部件都将集成在一起,散热还是一个需要考虑的问题。
为了优化内存的访问速度并减少跨核心延迟的同时兼顾设计和散热问题,现代处理器架构通常采用非统一内存架构 (Non-Uniform Memory Architecture, NUMA)。
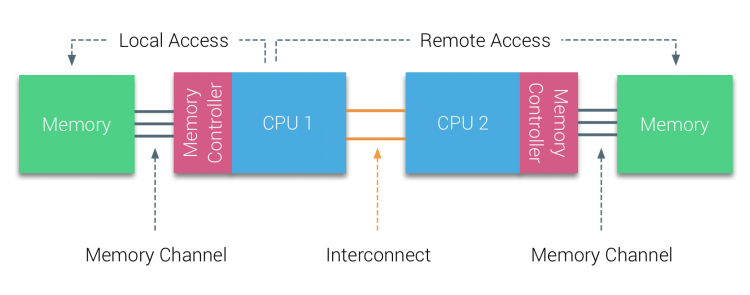
在 NUMA 架构下,每个 CPU (或者每个 CPU package)都使用自己的内存控制器去访问自己的本地内存 (local memory)。从而,在 CPU 访问本地内存时,系统就能够提供低延迟-高带宽的性能。我们也把 SoC + 本地内存的这样一个 cluster 称为 NUMA node。这种架构通过引入拓扑感知的内存访问方式避免传统 UMA 架构中因总线导致的访问延迟。
NUMA 架构中,各个 NUMA 节点之间通过 CPU 总线或专用的互联协议高速互联。如果一个 NUMA 节点想要去访问其他的 NUMA 节点中的内存,那么跨 NUMA 节点的远程内存访问就会引入额外的延迟和带宽损耗,从而使得访问效率显著下降。
假如一个任务在 Node 0 上运行,这个任务要访问的资源在 Node 1 的内存里,就需要通过互连总线把数据从 Node 1 传输到 Node 0 中。对于内存密集型的任务,不同 NUMA 节点之间的数据交互会带来额外的通信开销,影响性能。(还可能造成处理器前端的 installation)
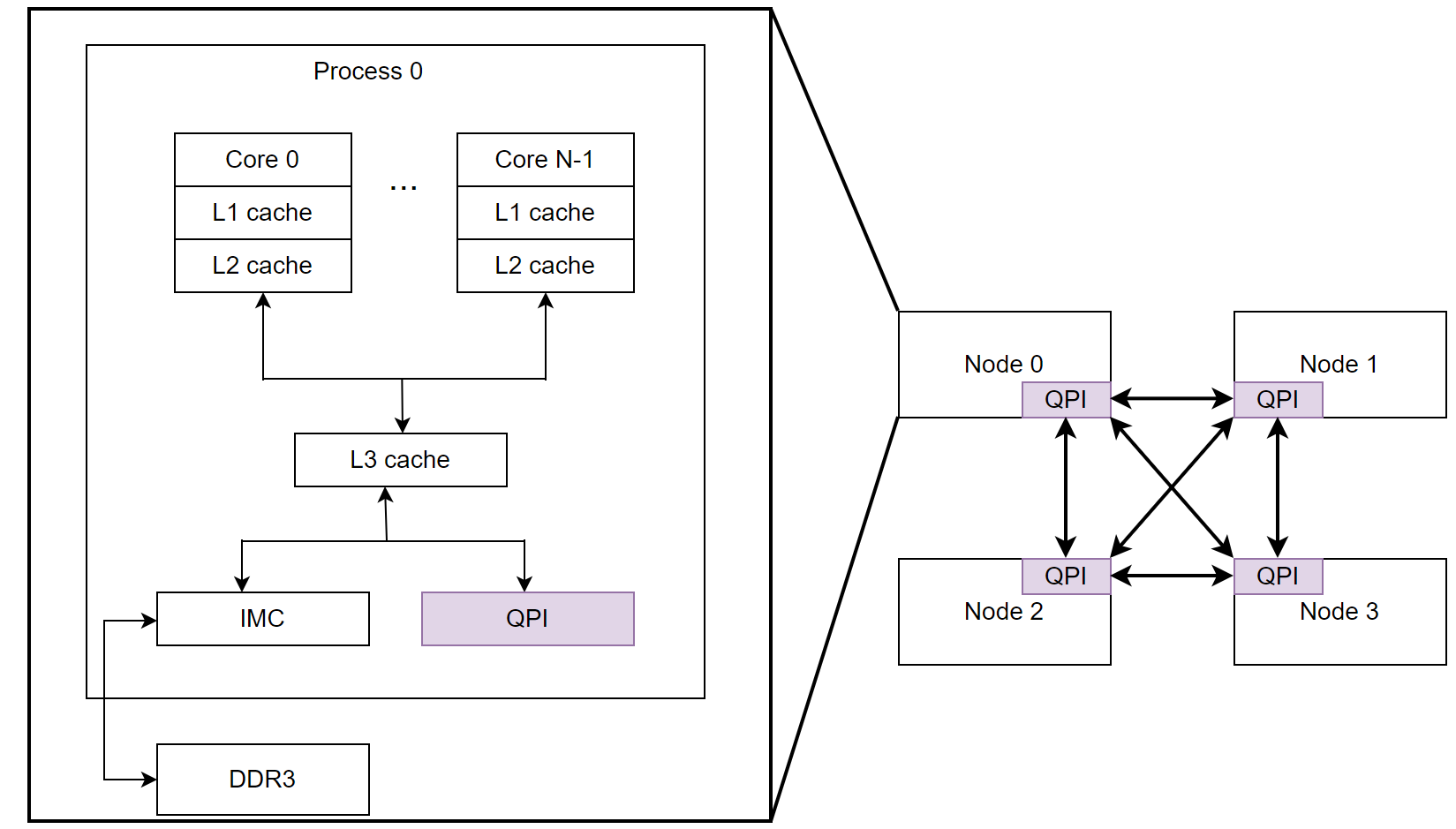
所以在 NUMA 系统中,我们可以通过将任务绑定在一个 NUMA node 上来减少跨节点的访问,让代码和数据都在同一个 NUMA 节点上,这就是 NUMA-aware 的思想。在 Linux 中,系统提供了一些接口实现处理器亲和性和 NUMA binding:
lscpunumactlperl
The NUMA Nodes are NOT Equal
不同 NUMA 节点拥有的资源可能是不一样的,因为每个节点都拥有自己的 IO 控制器。假如网卡在 NUMA 节点 0 的 PCIe 插槽,那么它的 DMA 操作就会有限访问节点 0 的本地内存,如果网络处理线程运行在节点 1,那么就会跨节点远程内存访问,增加延迟。
Q?
NUMA 系统中,如果数据在 NUMA node-1 的 L3 cache 中,NUMA node-2 运行的线程需要使用数据,那么数据会从 NUMA node-1 中的 L3 cache 复制到 NUMA node-2 上的 L3 cache 还是转移?